Sync Postgres and ElasticSearch using Hasura today

Gunar Gessner
Feb 24, 2020
Hi there 👋 In this post we're going to leverage Hasura to seamlessly, automatically, and continuously sync a Postgres database into denormalized ElasticSearch documents.
# Why sync Postgres to ElasticSearch?

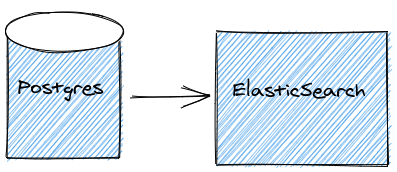
Syncing Postgres to ElasticSearch
If searching is a core feature of our app, we will want to use ElasticSearch. Although Postgres does have a Full Text Search feature, it doesn't scale well---especially when the requirements include searching across multiple tables.
ElasticSearch is ubiquitous when we're talking about search engines. It is speculated that for a number of years Lucene (its underlying library) powered all of the Google search engine. ElasticSearch generates multiple indexes for each document inserted and that is how it manages to be so fast
So, how do we sync Postgres data to ElasticSearch ?
At the bottom of this post you'll find a number of open-source, self-hosted projects that have implemented solutions for this problem. Maybe you will like one of them. However, if we already have Hasura set up, the amount of code we actually have to write so little, that instead of adding another dependency to our application, we might prefer to write the glue-code ourselves. This is what we will be doing here.
# Pulling data from Postgres

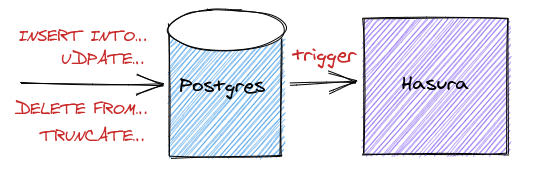
Setting up Hasura to observe database changes
Hasura will be doing the heavy-lifting for us. It allows us to trigger webhooks on database events like INSERT, UPDATE, and DELETE. Hasura also manages the queue, handles errors and retries, and provides a web interface to inspect pending events and processed events. No need for Debeezium nor Kafka.

Hasura event settings screen
You can find more information about Hasura Events at Hasura Docs: Event Triggers.
# Transforming the data

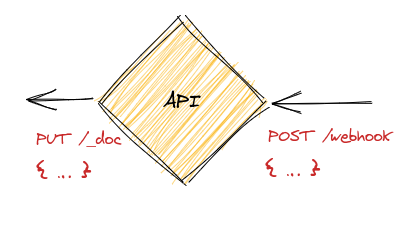
Transforming the received row into a denormalized document
Data stored in Postgres is relational in nature. Although ElasticSearch does implement the Join Datatype, the documentation explicitly tell us that de-normalization is key to good performance.
What is denormalization?
For the purposes of the present article we can think of denormalization as nothing more than just "expanding IDs into full blown objects."

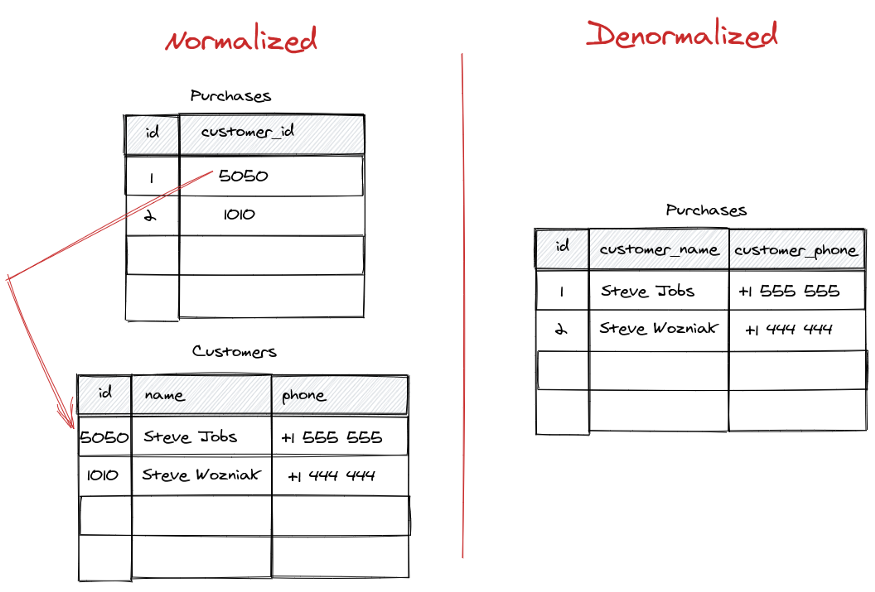
Normalization vs Denormalization
How to denormalize the data?

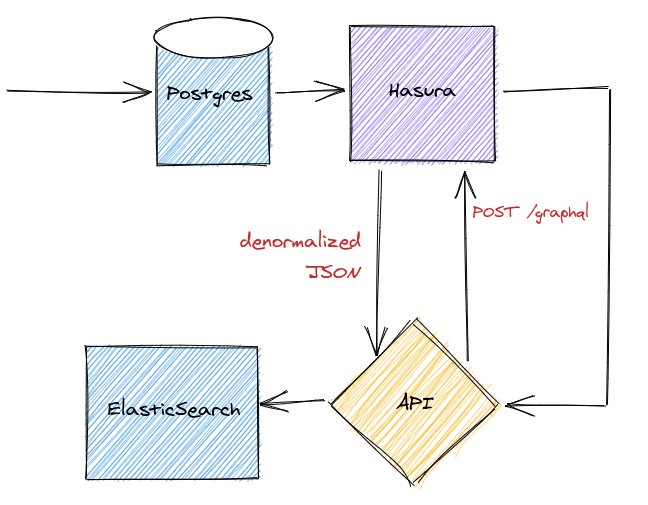
Using GraphQL to denormalize data
We could use SQL JOINs in order to denormalize the data, but you know what else is great at denormalizing stuff? GraphQL! When you think of it, denormalization is one of the biggest benefits of GraphQL. It's a core feature of the protocol. And since we already have Hasura set up, we get our GraphQL API for free.
query MyQuery($id: uuid!) {
purchases_by_pk(id: $id) {
id
customer {
name
phone
}
}
}
# Pushing the transformed data to ElasticSearch

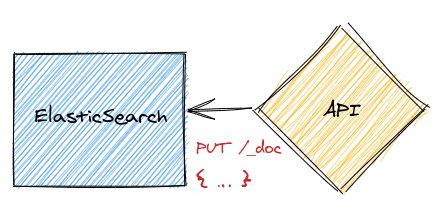
The response from the GraphQL API is in the JSON format, which means we can push it directly into ElasticSearch.
ElasticSeach's API is a REST API, so we can use the PUT verb for row insertions and updates, and the DELETE verb for row deletions. Here's one example:
PUT http://localhost:9200/purchases/_doc/1 { customer: { name: 'Steve Jobs', phone: '+1 555 555', } }
# Conclusion

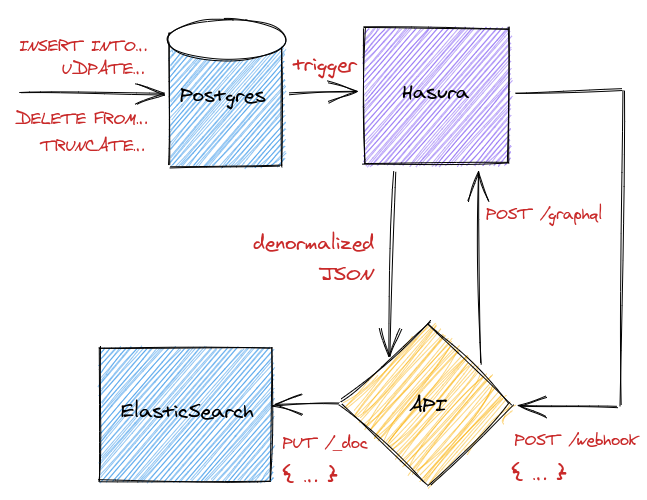
There we go, the plan for a complete one-way sync from Postgres to ElasticSearch. Here we have not written any actual code here---as the code would depend on your specific data structure and business needs---but my experience is that we would need to write just a little bit of glue code.
Hasura reminds me of a Swiss Army knife. Once in our stack, it allows us to insert, mutate, query, and stream data in a myriad of ways. Looking forward to hearing about your experience in the comments.
# Prior work
- zombodb is a postgres extension that implements custom indexes. Updates to tables indexed by zombo trigger calls to the ElasticSearch API to update documents. Zombodb also allows us to run ElasticSearch queries from within SQL-land.
- pg-sync is a python library that not only captures data changes but also allow us to use JSON configurations to transform the data (e.g. denormalizing).
- abc is a CLI tool written in go, built by appbase.io, which can be used to sync Postgres/SQL/Mongo to ElasticSearch.
NB: Out of the options above, only pg-sync gives us an elegant API with which to denormalize our data.

