Storing Google Takeout on AWS Glacier

Gunar Gessner
Mar 29, 2021
tl;dr Use cliget to fetch the URLs, then on a VPS pipe curl into aws s3 cp.
After numerous posts on HackerNews about Google locking people out of their accounts, I've decided to take initial steps towards securing my data.
Google Takeout allows you to download all your data. I don't remember the specifics but I'm pretty sure they were forced to offer it to comply with GDPR. The downloaded archive can contain your GDrive, GMail, Google Photos, and a whole bunch of other stuff you've probably forgotten you even had.
But where to store these huge files?
# Costs
My own Google Takeout archive is 400GB big. It costs me $0.40/mo in AWS storage and would cost me $35 if I ever needed to download it.
Downloading is expensive because it incurs outbound data transfer fees. It's cheap if you consider that I hope—knock-on-wood—to never need to access this backup.
Finally, the process I've used to download the data and upload to AWS requires a VPS, which has cost me a one time fee of $0.40.
You can run your own estimates using the AWS Calculator.
Glacier vs Deep Archive
Should you use Glacier or Deep Archive? You'll notice the fee of early deletion is 2x larger for Deep Archive but this difference is dwarfed by the 75% storage price discount. Deep Archive is always cheaper.


Comparison of Glacier vs Deep Archive
I'll walk you through the process of exporting a backup from Google Takeout and uploading it to AWS S3 Glacier.
What you'll need
- An AWS S3 Bucket
- An AWS EC2 server (I suggest the smallest one the t4g.nano)
- Firefox with the cliget extension
# 1. Request a Google Takeout archive
Go to Google Takeout and create a new export.
I strongly suggest you pick the file type .tgz, so that you can set the size of each part to be 50GB. The more files there are, the longer this process will take.

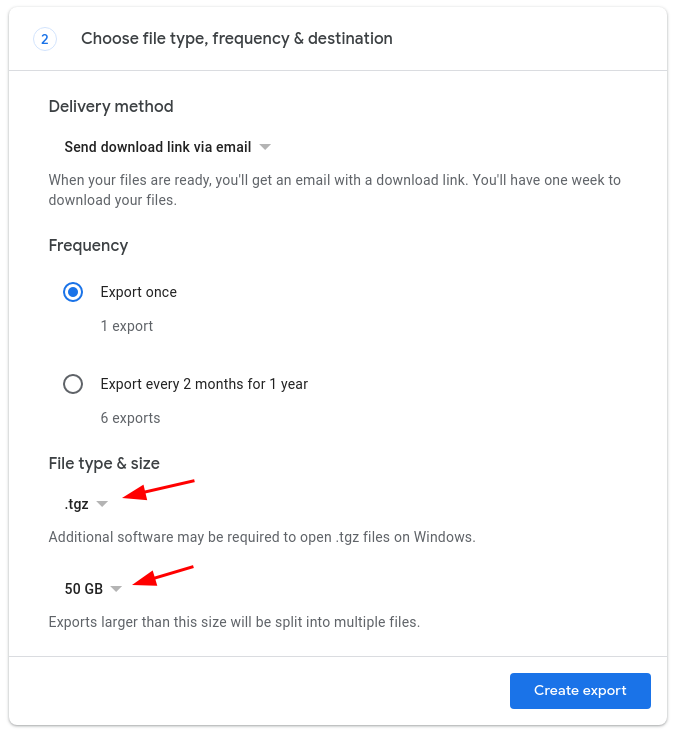
Delivery method
# 2. Prepare your VPS
In theory you can avoid renting a VPS from EC2 by using AWS CloudShell directly. In practice it doesn't work because the CloudShell will automatically close after 20 minutes of inactivity and transferring 50GB .tgz files form Google Takeout takes more than 1 hour.
Although you could rent a VPS elsewhere (e.g. Google Cloud or Vultr), it's ergonomic to have the server in the same data center as the S3 bucket.
Create an EC2 instance (the t4g.nano is enough) and ssh into it. Copy the script below and replace <your-bucket-name> with—guess what—your bucket name.
If you're going to encrypt your data on the client-side (I would), then replace <your-email-address> with your GPG key's email address. Also make sure to import the key with gpg --import.
Otherwise, just remove the gpg line below.
dl.sh
##!/usr/bin/env bash
## Usage: ./dl.sh curl …
## XXX: Set your bucket name here
AWS_S3_BUCKET="<your-bucket-name>"
## XXX: Set your gpg encryption email address here (or remove the `gpg` line)
GPG_EMAIL="<your-email>"
## Gets last argument
filename=${*:16:1}
## Gets all but the last 3 arguments
args=("${@:2:$#-3}")
echo "Downloading: $filename"
## Expands all args (i.e. `args[@]`) in a format that can be reused as input (i.e. `@Q`)
curl "${args[@]@Q}" \
| gpg --encrypt -r ${GPG_EMAIL} --trust-model always \
| aws s3 cp - "s3://${AWS_S3_BUCKET}/${filename}" \
--storage-class DEEP_ARCHIVE
Optional: Create a swapfile
During my experiments with a t4g.nano, 0.5GB of RAM seems enough, but I recommend creating a swapfile just in case. It helps to prevent the ssh session becoming unresponsive.
Here's a working snippet that creates a 1GB swapfile:
sudo dd if=/dev/zero of=/swapfile count=1024 bs=1M sudo chmod 600 /swapfile sudo mkswap /swapfile sudo swapon /swapfile echo "/swapfile none swap sw 0 0" | sudo tee -a /etc/fstab
# 3. Generate download URLs
Google Takeout archives can be downloaded from a browser only.
Google doesn't offer a URL that works with curl.
Of course you can use your browser and download them all normally, but you'd be limited by your
computers storage and most importantly by your home internet connection—which is required twice, once for downloading from Google and once to upload to AWS.
The only solution I've found is to use the Firefox extension called cliget. This extension allows you to copy the URL of a download—including headers and cookies—before the download starts.
I've looked for Chromium-based alternatives but it doesn't seem like there are any. If Firefox is not your main browser, you can always install it just for the sake of this process.
Wait for email confirmation that your takeout is ready.


email from Google
Spin up Firefox and navigate to Google Takeout. Click to download the first part. When the Download modal opens, dismiss it and click on the extension icon instead.

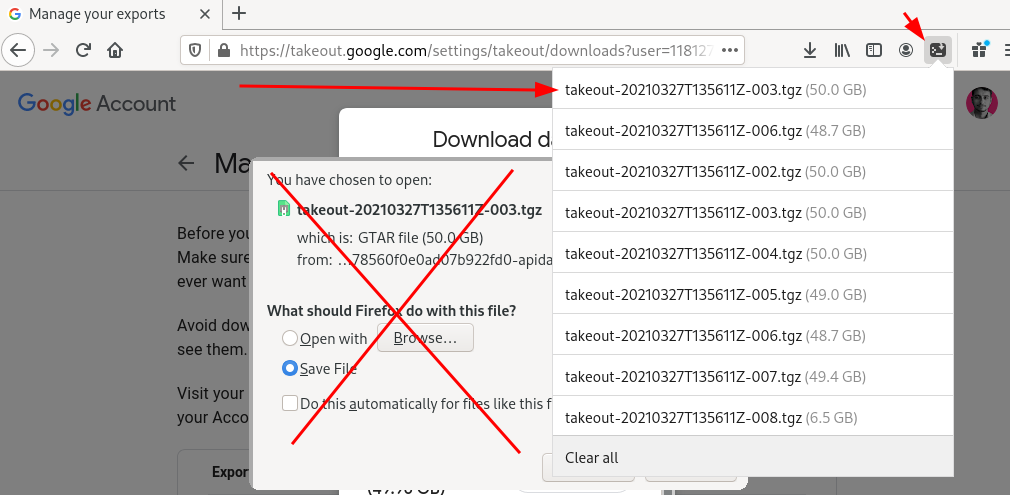
cliget
Copy this text, we're going to use it in the next step.

cliget
# 4. Transfer the files
On your VPS (ssh), call dl.sh and use as arguments the command line copied from cliget—starting with curl and ending with --output — e.g. ./dl.sh curl …. Do this for each part.
You'll notice the download slows down after a while. Starts at 13MB/s and slows down to less than 1MB/s. I've checked CPU and RAM usage, and even checked the network bandwidth but couldn't find the bottleneck. I'm pretty sure it's just Google's servers throttling the downloads.
# 5. All done
After kicking off downloads for each file part, and waiting a few hours for it to complete, I'd managed to have the whole 400GB of my Google Takeout stored in AWS Deep Archive for $0.40/mo.

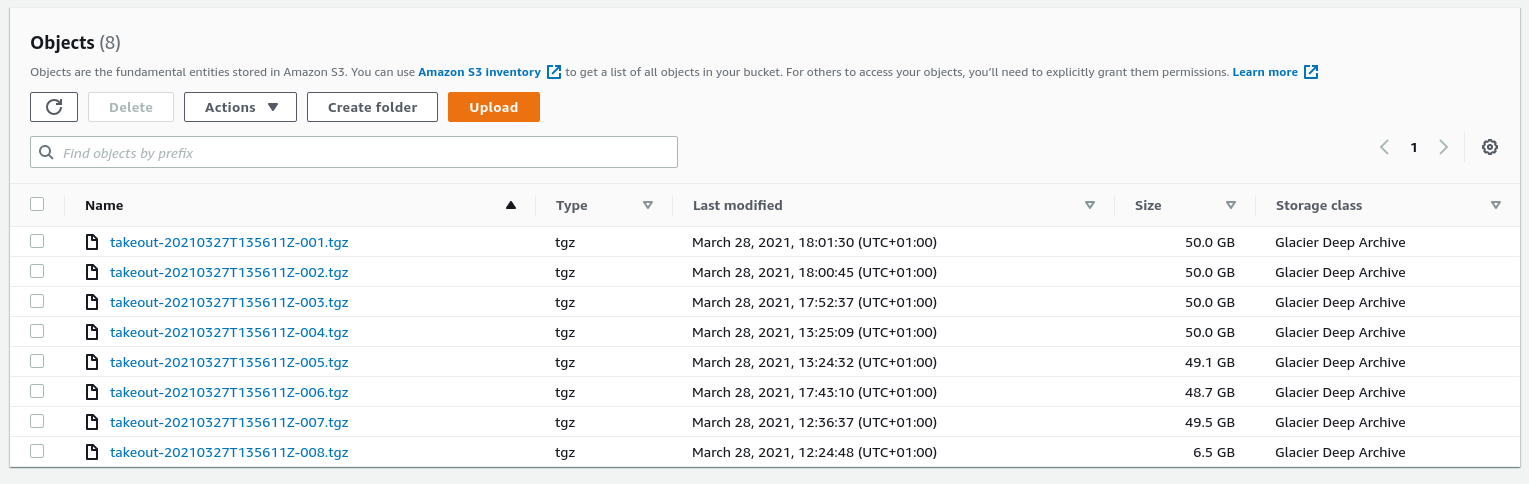
s3
Friendly reminder. If you're on GMail, please set up a custom domain. It'll allow you to forward your emails to a different provider should the worst ever happen.

