We went monorepo

Gunar Gessner
Nov 5, 2018
In October we decided to make a horizontal investment in speed and decided to go monorepo with our services architecture. Naturally, we still want to be deploying to microservices for scalability and resilience — so it’s not a monolith, it’s a monorepo. And I was entrusted with the implementation.
# The benefits
There are quite a few benefits to the monorepo architecture, and three of them stood out for us.
1. Code review
Code changes to multiple different microservices can be contained in a single pull request. So you have the full scope of the change in a glimpse. You can even release new versions of packages and update the services that consume them at the same time.
2. End-to-end testing
We must admit, in favor of being nimble we’ve been skipping writing E2E tests, but now for DAL2 we’re ready to make the commitment. We want to write Unit Tests, then E2E Tests, and only write Integration Tests where absolutely necessary (because in my experience, the latter carries the highest maintenance costs).
The monorepo will simplify this process. There are a couple of ways we can implement them in the monorepo architecture, and we’re still working on it, so I’ll leave it another report (next month?).
3. One deployment per Pull Request
This is the (my) holy grail. I want us to be able to develop locally, push changes to the cloud, and have our infrastructure spin up the whole thing. Imagine working on a feature and being able to provide to the stakeholders with a unique URL for them to test, knowing that (1) that’s exactly how the system will behave once merged into production, and that (2) they can fiddle around as much as they want, as this environment is not shared with production nor a centralized staging environment. We’re not there yet, but that’s where we want to get.
# The setup
File structure
We’re using lernajs alongside yarn workspaces to manage dependency installation and linking, and running tests for every service.

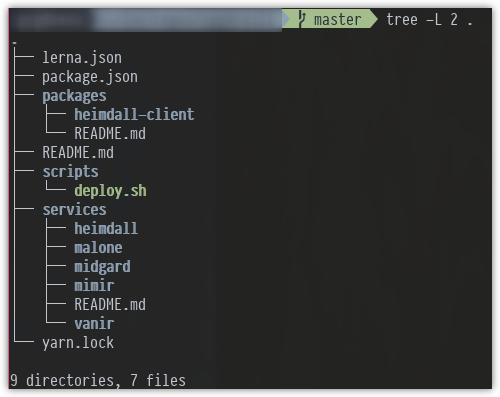
So far we have ported to the monorepo 5 services and 1 package.
CI Workflow
We’re using CircleCI for testing and deployment. We use a custom .circleci/config.yml file, that calls lerna for tests, and calls a custom bash file for deployment (scripts/deploy.sh).

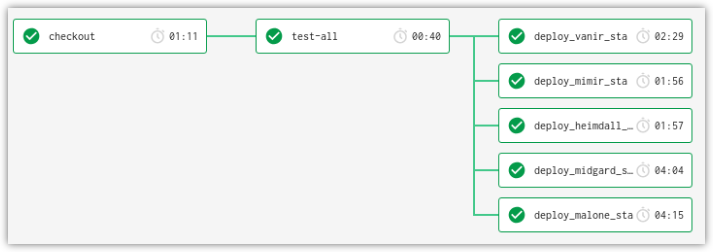
A successful `deploy` workflow. Note that services are deployed in parallel.
Dockerfile
We’re basing our image on the Alpine disto. Then doing a little PATH magic, and using yarn for dependencies.
FROM alpine:latest WORKDIR /usr/src/app RUN apk add --no-cache --update 'nodejs~8' yarn RUN yarn global add node-gyp RUN export PATH=$PATH:./node_modules/.bin # http://bitjudo.com/blog/2014/03/13/building-efficient-dockerfiles-node-dot-js/ ADD package.json yarn.lock ./ RUN yarn install -s --ignore-scripts ADD . . RUN yarn build CMD ["yarn", "start"]
Dockerhub
Our deploy script builds the docker image on the cloud (CircleCI) then pushes the images to Dockerhub. CircleCI has their own Docker Caching Layer so it skips redundant builds. Good job, CircleCI!

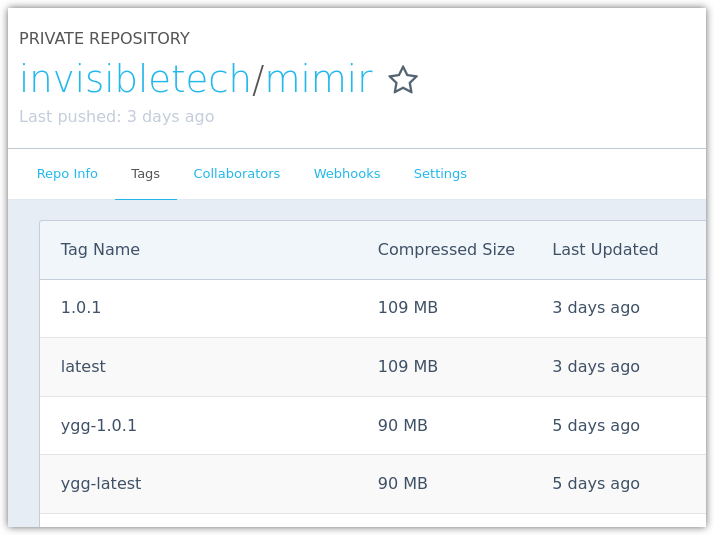
All image names were prefixed with `ygg` to avoid conflicts and overwrites during the transition.
Heroku
We host our code on Heroku, and we were delighted to learn that Heroku has their own Docker Registry, so pushing an image is as simple as docker push registry.heroku.com/<repo>/<service>:<tag>.

The end result. It's deployed!
To level with you, after pushing the image, you still have to release it. Here’s the code
#!/bin/sh http_code=$(curl -s -o out.json -w '%{http_code}' -n -X PATCH https://api.heroku.com/apps/$HEROKU_APP_NAME/formation \ -d "{ \"updates\": [ { \"type\": \"web\", \"docker_image\": \"$IMAGE_ID\" } ] }" \ -H "Content-Type: application/json" \ -H "Accept: application/vnd.heroku+json; version=3.docker-releases" \ -H "Authorization: Bearer $HEROKU_API_KEY" \ ;) # Display output on the screen cat out.json if [[ $http_code -eq 200 ]]; then echo "****** Image successfully relased (Heroku)" exit 0 fi echo "****** There was an error when trying to release the image" exit 1
# Reviewing the first PR to the Monorepo
In order to send this PR for review I was careful to keep the git history as clean as possible. As this is a new repo, I wanted master to be clean and everything to be on the first PR. This meant a lot of rebasing :)

Can you guess what “Batman” stands for?

Merging existing repos into the monorepo while dealing with open PRs was tricky, so these commit messages are not consistent with semantic types, but will be, moving forward.
And I even learned how to split a commit in two while cleaning up the history, which I readily shared with the team (and with Twitter).
git rebase -i <oldsha1> # mark the expected commit as `edit` (i.e. replace pick in front of the line), save and close git reset HEAD^ git add . git commit -m "First part" git add . git commig -m "Second part" git rebase --continue
I’m stoked about the peace of mind the monorepo architecture provides to my team and me, and what it will yield us in terms of speed and quality.

